CoNLL 2008 Shared Task: Joint Learning of Syntactic and Semantic Dependencies
Mihai Surdeanu, Richard Johansson, Adam Meyers, Lluís Màrquez, Joakim Nivre
The CoNLL 2008 shared task focuses on the joint learning of
syntactic and semantic dependencies.
The task merges syntactic dependencies (extracted from the Penn Treebank) and semantic dependencies (extracted from PropBank and NomBank) under a unique unified representation that supports the correct and efficient representation of all phenomena of interest.
Conceptually, this shared task can be divided into three
subtasks: (i) parsing of syntactic dependencies, (ii) identification
and disambiguation of semantic predicates, and (iii) identification
of arguments and assignment of semantic roles for each predicate.
Several objectives were addressed in this shared task:
Semantic role labeling (SRL) is performed and evaluated using a dependency-based representation
for both syntactic and semantic dependencies. While SRL on top of a
dependency treebank has been addressed before [Hac04], this
approach addresses several novel issues: (i) the constituent-to-dependency
conversion strategy transforms all
annotated semantic arguments in PropBank and NomBank not just a subset;
(ii) we address propositions centered around both verbal (PropBank)
and nominal (NomBank) predicates.
Based on the observation that a richer set of syntactic
dependencies improves semantic processing [Joh07], the
syntactic dependencies modeled are more complex than the ones used
in the previous CoNLL shared tasks. For example, we now include
apposition links, dependencies derived from named entity (NE)
structures, and better modeling of long-distance grammatical
relations.
A practical framework is provided for the joint learning of
syntactic and semantic dependencies.
The evaluation is separated into two
different challenges: a closed challenge, where
systems have to be trained strictly with information
contained in the given training corpus, and an
open challenge, where systems can be developed
making use of any kind of external tools and resources.
Please see Section 2.1 of the task description paper for the description of the data format for both challenges. For clarity, we include here a small example of the training data for the closed challenge, as well as an example of the training data for the open challenge.
The entire dataset is released through LDC.
Post evaluation, the dataset is available for free to LDC members.
For clarity, we include the dataset's README here.
The official evaluation measures consist of three
different scores: (i) syntactic dependencies are
scored using the labeled attachment score (LAS),
(ii) semantic dependencies are evaluated using a
labeled F1 score, and (iii) the overall task is scored
with a macro average of the two previous scores.
Please see Section 2.2 of the task description paper for the
formal definition of the evaluation measures.
The official scorer for shared task is eval08.pl v1.8. After downloading the scorer file, please rename it from eval08.txt to eval08.pl. Then execute it as: [perl] eval08.pl [OPTIONS] -g <gold standard> -s <system output>.
Results
Nineteen groups submitted test runs in the closed
challenge and five groups participated in the open
challenge. Three of the latter groups participated
only in the open challenge, and two of these submitted
results only for the semantic subtask.
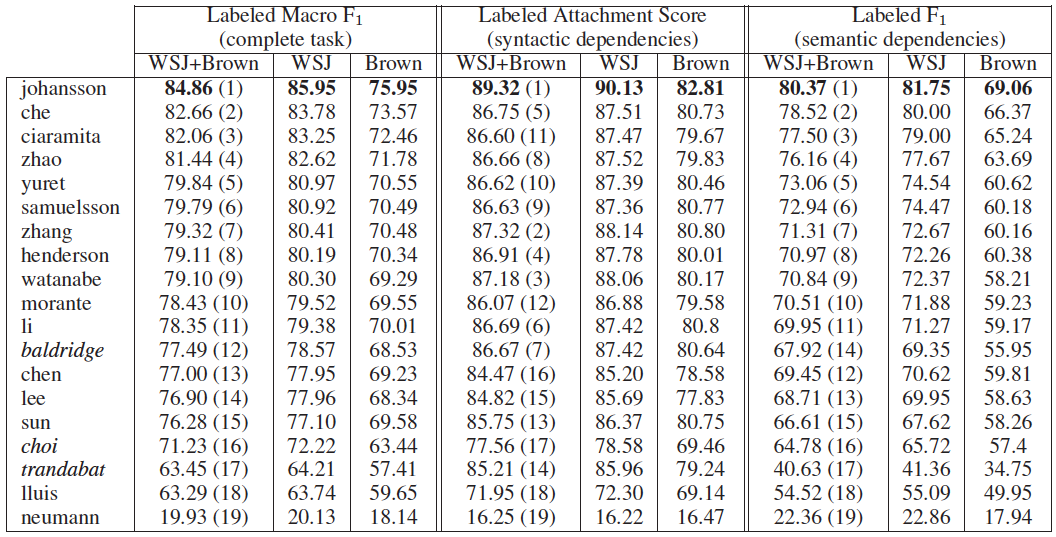
The results for the closed challenge are summarized below:
In the table, teams are denoted by the last name of the first author of the corresponding paper in
the proceedings or the last name of the person who registered the team if no paper was submitted.
Italics indicate that there is no corresponding paper in the proceedings. Results are sorted in descending
order of the labeled macro F1 score on the WSJ+Brown corpus. The number in parentheses next to the
WSJ+Brown scores indicates the system rank in the corresponding task.
In a similar format, the results for the open challenge were:
Please see Sections 4 and 5 of the task description paper for a discussion of these results.
The papers associated with the participating systems can be found in
the reference section below.
The outputs of all the participating systems on the test partitions are available here. The official scores for all these submissions are available here.